1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
| # PinyinDataCrawler.py
import random
import requests
import json
import pymysql
from Logger import logger
from Config import config
header_str = '''Host:hanyu.baidu.com
Connection:keep-alive
sec-ch-ua:"Chromium";v="92", " Not A;Brand";v="99", "Microsoft Edge";v="92"
Accept:application/json, text/javascript, */*; q=0.01
X-Requested-With:XMLHttpRequest
sec-ch-ua-mobile:?0
User-Agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 Edg/92.0.902.67
Sec-Fetch-Site:same-origin
Sec-Fetch-Mode:cors
Sec-Fetch-Dest:empty
Referer:https://hanyu.baidu.com/s?wd=%E5%8F%B7%E8%AF%8D%E7%BB%84&from=poem
Accept-Encoding:gzip, deflate, br
Accept-Language:zh-CN,zh;q=0.9,en;q=0.8,en-US;q=0.7
Cookie:填写自己的Cookie'''
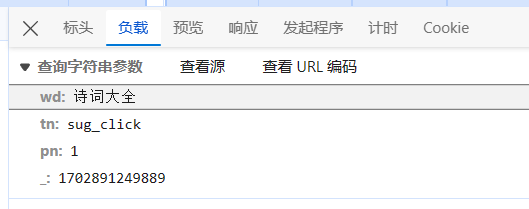
params_str = '''wd=%E5%8F%B7%E8%AF%8D%E7%BB%84
from=poem
pn=1
_=1628826451938'''
class PinyinDataCrawler:
homographWeightDict = dict()
def __init__(self):
self.conn = self.getConnection()
self.character_list = self.getAllCharacters()
f = open("./data/luna_pinyin.dict.yaml", "r", encoding='utf8')
for line in f.readlines():
datas = line.strip().split('\t')
if len(datas) == 3:
word = datas[0]
pinyin = datas[1]
weight = datas[2]
if word not in self.homographWeightDict:
self.homographWeightDict[word] = dict()
if pinyin not in self.homographWeightDict[word]:
self.homographWeightDict[word][pinyin] = dict()
self.homographWeightDict[word][pinyin] = weight
def getHomograph(self, word="不"):
return self.homographWeightDict.get(word, dict())
# 把所有的多音字进行识别
def splitHomograph(self, path='./Clover四叶草拼音', newPath='./Clover四叶草拼音new'):
if not os.path.exists(newPath):
os.mkdir(f'{newPath}')
for file_now in os.listdir(path):
new_file_path = os.path.join(newPath, file_now)
curr_path = os.path.join(path, file_now)
new_file = open(new_file_path, 'w', encoding="utf-8")
if 'base' not in curr_path:
continue
for line in open(curr_path, encoding='utf-8'):
if "\t" in line:
keyword = line.split('\t')[0]
pinyin_old = line.split('\t')[1].strip()
count_str = line.split('\t')[-1].strip().replace(" ", '')
pinyinDict = self.getHomograph(keyword)
if len(pinyinDict) == 0:
new_file.write(line)
new_file.flush()
else:
currPinyins = sorted(pinyinDict.items(), key=lambda x: x[1], reverse=True)
for currPinyin in currPinyins:
try:
newLine = line.replace(pinyin_old, currPinyin[0]).replace(count_str, currPinyin[1])
new_file.write(newLine)
new_file.flush()
except Exception as e:
print(e)
else:
new_file.write(line)
new_file.flush()
new_file.close()
def format_header(self, header_str=header_str):
header = dict()
for line in header_str.split('\n'):
header[line.split(':')[0]] = ":".join(line.split(':')[1:])
return header
def format_params(self, params_str=params_str):
params = dict()
for line in params_str.split('\n'):
params[line.split('=')[0]] = line.split('=')[1]
return params
def getPlainPinyin(self, sug_py):
splits = ['a', 'o', 'e', 'i', 'u', 'ü']
shengdiao = '''a ā á ǎ à
o ō ó ǒ ò
e ē é ě è
i ī í ǐ ì
u ū ú ǔ ù
ü ǖ ǘ ǚ ǜ'''
shengdiaoToWord = dict()
for line in shengdiao.split("\n"):
datas = line.split(' ')
for curr in datas[1:]:
shengdiaoToWord[curr] = datas[0]
plain_pinyin = ''
for curr in sug_py:
if curr not in shengdiaoToWord:
plain_pinyin += curr
else:
plain_pinyin += shengdiaoToWord[curr]
return plain_pinyin
def storeWord(self, word, currMean, word_index):
try:
pinyin = currMean.get("pinyin", "")
if len(pinyin) > 0:
pinyin = pinyin[0]
definition = currMean.get("definition", "")
if len(definition) > 0:
definition = "\n".join(definition).replace("'", '"')
if len(definition) > 4096:
definition = definition[:4096]
plain_pinyin = currMean.get("sug_py", "")
if len(plain_pinyin) > 0:
plain_pinyin = self.getPlainPinyin(pinyin)
pronunciation = currMean.get("tone_py", "")
if len(pronunciation) > 0:
pronunciation = pronunciation[0]
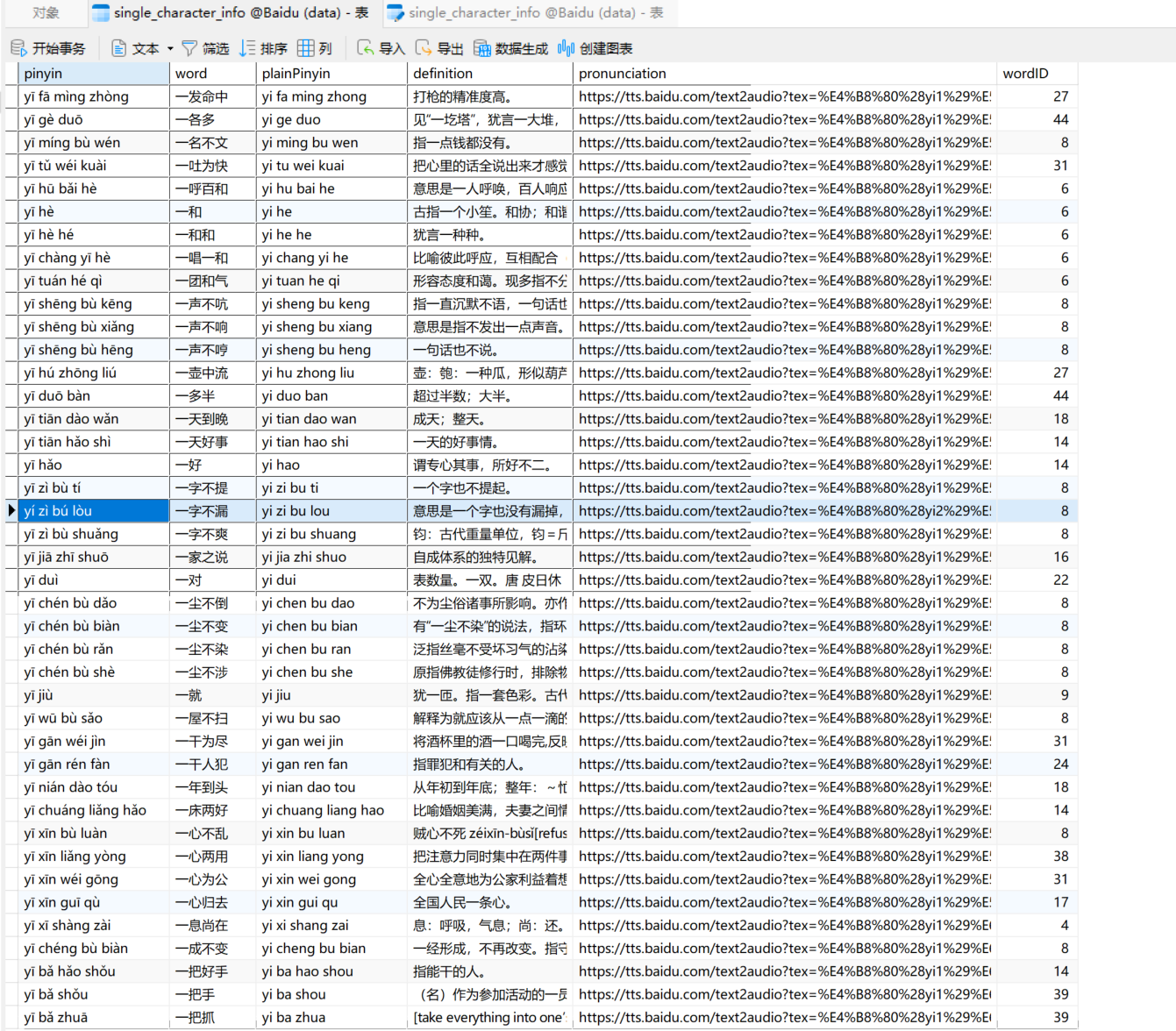
sql_str = f"insert into single_character_info values ('{pinyin}', '{word}', \
'{plain_pinyin}', '{definition}', '{pronunciation}', {word_index})"
cursor = self.conn.cursor(pymysql.cursors.DictCursor)
cursor.execute(sql_str)
self.conn.commit()
except Exception as e:
if "Duplicate" not in f"{e}":
logger.error(f"word: {word}, pinyin: {pinyin}, error_info: {e}")
def fixesDatas(self):
f = open('1.txt')
for line in f.readlines():
word = line.replace(" ", "").split(":")[-3].split(",")[0]
logger.info(f"更新词组[{word}]的数据")
headers = self.format_header()
params = self.format_params()
params["pn"] = 1
url = "https://hanyu.baidu.com/hanyu/ajax/search_list"
params['wd'] = word
while True:
try:
response = requests.get(url, params=params, headers=headers, timeout=(3.05, 10))
break
except Exception as e:
logger.error(f"error_info: {e}")
if 'timed out' in f"{e}":
continue
datas = json.loads(response.text).get('ret_array', list())
for currWordData in datas:
if 'mean_list' not in currWordData:
logger.warning(f"warning_info: {word} has not mean_list")
continue
currMeanList = currWordData["mean_list"]
try:
word = currWordData["name"][0]
for currMean in currMeanList:
self.storeWord(word, currMean, 0)
break
except Exception as e:
logger.error(f"error_info: {e}")
def parserDatas(self, word, datas, word_index):
for currWordData in datas:
if 'mean_list' not in currWordData:
logger.warning(f"warning_info: {word} has not mean_list")
continue
currMeanList = currWordData["mean_list"]
word = currWordData["name"][0]
for currMean in currMeanList:
self.storeWord(word, currMean, word_index)
def getConnection(self):
host = config["MYSQL"]["HOST"]
port = int(config["MYSQL"]["PORT"])
db = config["MYSQL"]["DATA_BASE_NAME"]
user = config["MYSQL"]["USERNAME"]
password = config["MYSQL"]["PASSWORD"]
conn = pymysql.connect(host=host, port=port, db=db, user=user, password=password)
return conn
def getCurrWordPageCount(self, url, params, headers):
pageCount = -1
while pageCount == -1:
try:
response = requests.get(url, params=params, headers=headers, timeout=(3.05, 27))
if len(response.text) == 0:
break
pageDatas = json.loads(response.text).get('extra', dict())
pageCount = pageDatas.get("total-page", 0)
except Exception as e:
logger.error(f"getCurrWordPageCount, error_info: {e}")
time.sleep(random.randint(5, 10))
logger.info(f"getCurrWordPageCount, pageCount = {pageCount}")
return pageCount
def crawlerExactPhrasePinyin(self, word="号", word_index=0, characters=None, phrase=True):
if characters is None and phrase is True:
characters = self.character_list
if characters is None:
characters = list()
headers = self.format_header()
params = self.format_params()
params["pn"] = 1
url = "https://hanyu.baidu.com/hanyu/ajax/search_list"
if phrase:
params['wd'] = word + "词组"
else:
params['wd'] = word
pageCount = self.getCurrWordPageCount(url, params, headers)
currPageIndex = 0
while currPageIndex < pageCount:
params["pn"] = currPageIndex
while params["pn"] == currPageIndex:
try:
logger.info(f"更新汉字[{word}]({word_index + 1} / {len(characters)})的词组数据(页数:{currPageIndex + 1} / {pageCount}) ")
response = requests.get(url, params=params, headers=headers, timeout=(3.05, 10))
datas = json.loads(response.text).get('ret_array', list())
self.parserDatas(word, datas, word_index)
currPageIndex += 1
except Exception as e:
logger.error(f"更新汉字{word}出现错误, 错误信息: {e}")
time.sleep(random.randint(5, 9))
time.sleep(random.randint(5, 100) * 0.01)
logger.info(f"更新汉字[{word}]的词组数据完成。")
def getAllCharacters(self):
file_path = './data/clover.base.dict.yaml'
file = open(file_path, 'r', encoding="utf-8")
character_list = list()
for line in file.readlines():
if '\t' in line:
word = line.split('\t')[0]
if word not in set(character_list):
character_list.append(word)
return character_list
def getCurrCharacterStoreIndex(self):
sql_str = 'select * from single_character_info order by wordID desc'
cursor = self.conn.cursor(pymysql.cursors.DictCursor)
cursor.execute(sql_str)
data = cursor.fetchone()
logger.info(f'getCurrCharacterStoreIndex data = {data}')
if data is None:
return 0
return data['wordID']
def crawlerPhraseDict(self):
characters = self.character_list
i = self.getCurrCharacterStoreIndex()
#i = 41318
while i < len(characters):
word = characters[i]
logger.info(f'开始更新汉字[{word}]({i + 1}/{len(characters)})的数据...')
self.crawlerExactPhrasePinyin(word, i, characters)
i = i + 1
logger.info(f'更新汉字[{word}]({i + 1}/{len(characters)})的数据完成!')
time.sleep(random.randint(1, 5) * 0.2)
if __name__ == "__main__":
PinyinDataCrawler().crawlerPhraseDict()
|